Introduction
It is a common occurrence when contracted by a company to do some data work, and we find ourselves staring at a dashboard that feels off, or hunting through a massive corporate library for that one elusive dataset, only to find a table with cryptic column names and no owner. Most organizations are swimming in what they call the new oil, but without a way to refine it, they end up with a data swamp instead of a strategic asset. That’s where you find yourself stuck in the quagmire, worried that the task you needed to complete in 2 weeks might actually take you more time.
To move from a disorganized data junkpile to a modern, scalable ecosystem, we have to stop treating data as a byproduct of our systems and start treating it as a product in its own right. In the world of Data Mesh, a data product is considered the architectural quantum, i.e., the smallest unit of architecture that can be independently deployed with everything it needs to function.
But what does that actually look like under the hood? Let’s perform an autopsy on the anatomy of a truly high-quality data product.
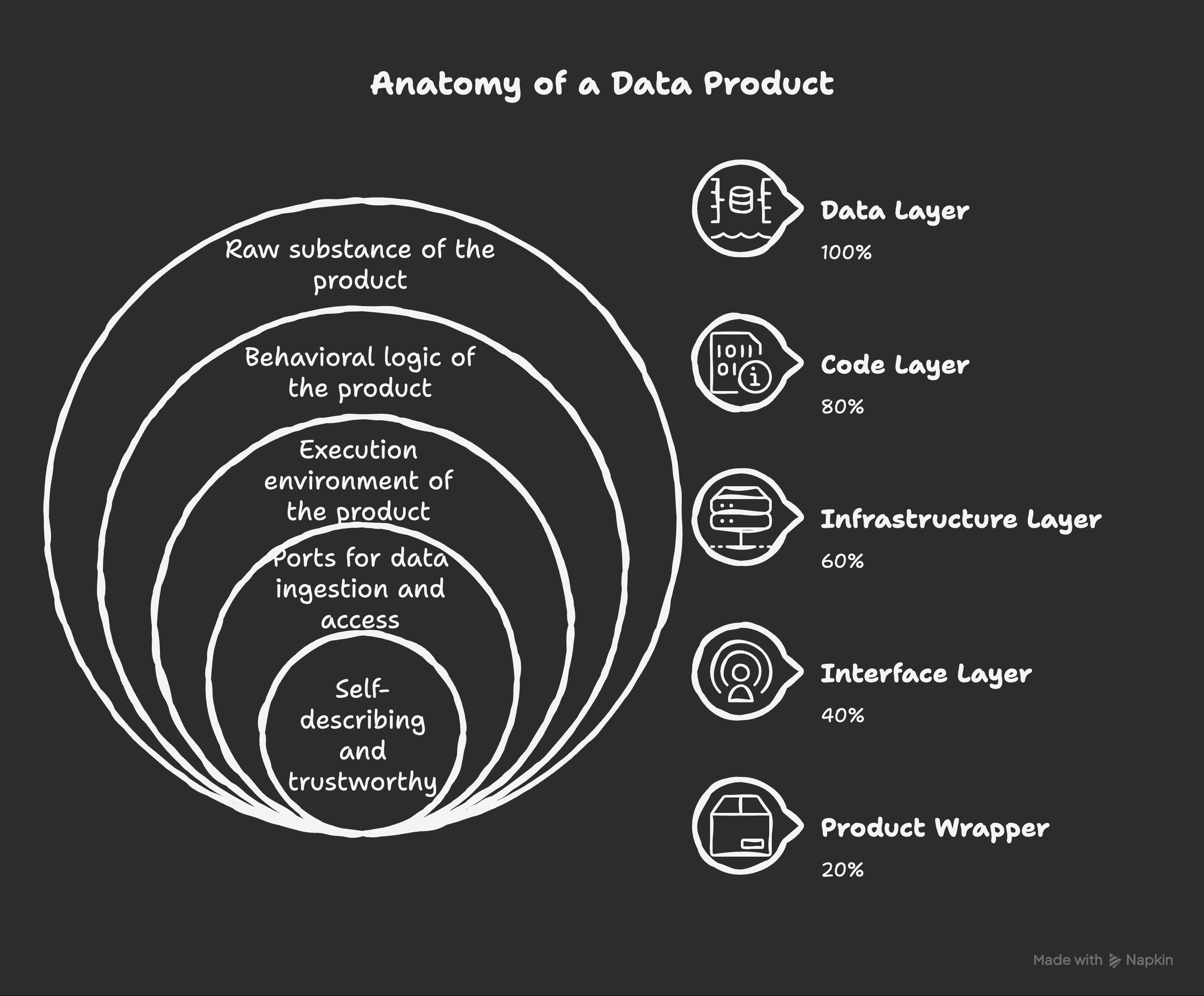
1. The Core (The Data Layer)
At the center of every data product is the Data Layer, its raw substance. This isn't just a static file; it can take many forms depending on the need:
- Fact and dimension tables in a warehouse like Snowflake or BigQuery.
- Real-time event streams via Kafka or Kinesis.
- Feature stores are designed specifically for machine learning models.
On its own, this layer is inert and potentially a liability if it lacks context. For most of the organizations with data swamps, this is what they have. To move them to a data product structure, this data must be managed as a unit, ensuring it is complete, clean, and compliant.
2. The Code Layer
If data is the core, Code is what makes it move. This layer contains the behavioral logic required to turn raw inputs into something a human or an AI can actually use. It includes:
- Transformation Logic (ETL/ELT): The SQL or Python scripts that clean and aggregate the data.
- Data Quality Tests: Automated checks (using frameworks like Great Expectations) that ensure revenue isn't negative or email addresses aren't null.
- Access Control: The code & policies that enforce who can see what, ensuring sensitive information is masked or redacted.
3. The Infrastructure Layer
A product can’t run without an engine. The Infrastructure Layer provides the execution environment, i.e., the compute, storage, and orchestration needed to keep the lights on. In a mature organization, this is often provided by a self-service data platform, allowing domain experts to focus on the "what" (the data) rather than worrying about provisioning servers or managing networking.
4. The Interface Layer (Ports)
A data product isn't a silo; it has to talk to the world. It does this through Input and Output Ports.
- Input Ports are how the product ingests data, often through asynchronous event streams to maintain near-real-time updates.
- Output Ports are the "purpose-driven" interfaces where consumers access the finished goods, whether that’s a SQL endpoint for an analyst, a REST API for a developer, or a file export for an external partner. This is how the marketing team shared their data product with the rest of the organization’s data consumers.
5. The Product Wrapper
This is perhaps the most critical part of the anatomy. The Product Wrapper is what makes the data self-describing and trustworthy. It consists of:
- Operational Metadata: Real-time stats on data freshness, lineage (where it came from), and uptime.
- Semantic Logic: The business definitions that ensure Revenue means the same thing to the Sales team as it does to Finance.
- The Sidecar Pattern: Think of this as a companion process that runs alongside the data product to handle cross-cutting concerns, such as audit logging and security policy enforcement.
The Smart Parcel Analogy
To make the idea of a data product relatable, imagine a Smart Parcel.
The data is the item inside the box. On its own, it’s just a thing. But a data product is the entire package. The wrapper is the shipping label telling you where it came from, the tracking number showing its current state, the customs declaration explaining what’s inside, and a digital lock that only opens for the right recipient.
Organizations that move data without these layers are essentially shipping unlabeled boxes in the dark, then acting surprised when the delivery fails or the contents are damaged.
Conclusion
The anatomy of a data product isn't just a technical checklist; it's a cultural shift. It moves accountability to a Data Product Manager who is responsible for its success, ROI, and user satisfaction.
When you build with this anatomy in mind, your data stops behaving like a swamp and starts behaving like infrastructure you can actually build a business on.
