Introduction
In the modern data landscape, there is a hard truth we all have to face, having data is not the same as having a data product. For years, organizations have treated data as a byproduct of systems — essentially the exhaust left behind by applications. This approach led to disorganized data junkpiles, where analysts spent 80% of their time cleaning data rather than generating insights.
To achieve true success today, we must shift toward data product thinking. A successful data product is the architectural quantum of a modern data ecosystem, a self-contained, high-quality, and trustworthy asset designed to solve a specific business problem.
But how do we measure that success?
It isn't just about a successful pipeline run; it's about a holistic view of adoption, quality, impact, and user delight.
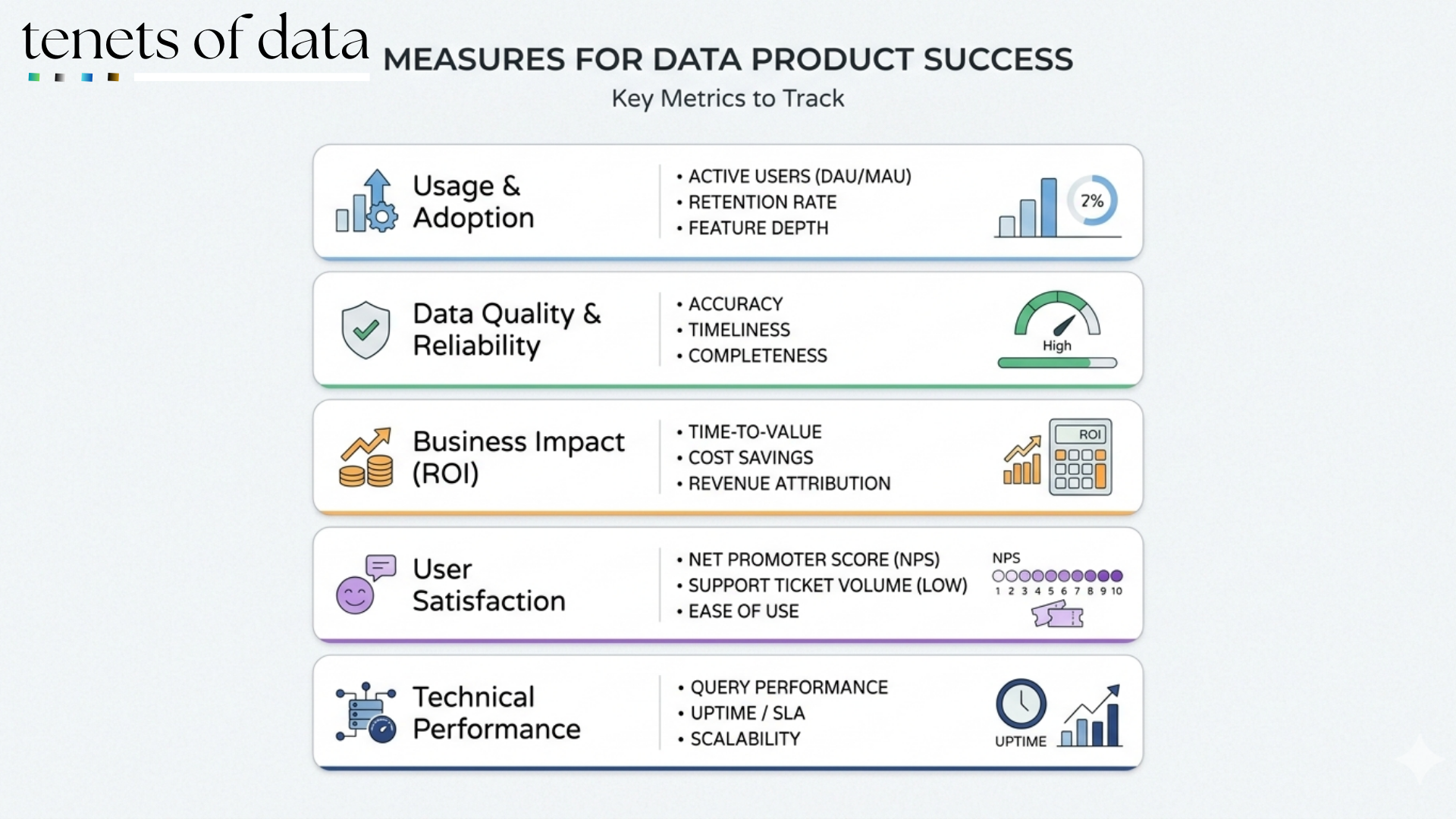
1. Usage and Adoption
The most sophisticated dashboard in the world is a failure if no one opens it. In a successful data product ecosystem, high-value data is used frequently and integrated deeply into daily workflows. We move away from vanity metrics and instead track active users, query volumes, and dashboard views to gauge true adoption.
High adoption is the loudest signal that you are turning data investments into real business impact. When a team building a recommendation engine can discover an existing anonymized customer dataset in a catalog and request access immediately, the friction of innovation disappears. Success means your data is discoverable and addressable, allowing teams to spend less than the typical 4 hours a day just searching for information.
2. Data Quality and Reliability
Trust is the most difficult attribute to maintain at scale. If consumers can't trust the data, they won't use it, regardless of how "discoverable" it is. Successful data products treat quality as a continuous property, not a one-off cleaning exercise.
True reliability is built on seven dimensions: usefulness, accuracy, completeness, consistency, uniqueness, validity, and freshness.
High-performing teams don't just hope the data is good; they publish Service Level Objectives (SLOs) that define acceptable thresholds for freshness and accuracy. When quality metrics are visible—such as "99.5% of records have a valid email"—trust becomes measurable rather than anecdotal.
3. Business Impact and ROI
At the end of the day, a data product exists to generate value. Successful products are tied directly to the business outcomes that matter, that is, revenue growth, cost savings, risk reduction, and time saved.
We must ask: Does this product shorten sales cycles? Does it reduce customer churn by 5%?. By mapping data capabilities to strategic objectives (OKRs), data leaders can prove that their work isn't just a cost center but a strategic asset. For example, California Design Den saw a 50% reduction in inventory carryover after utilizing a data product for e-commerce, directly boosting profit margins.
4. Speed as a Feature
Technological excellence in data products is defined by agility and performance. A key metric here is time-to-insight—the duration from a business question to a data-backed answer.
The underlying infrastructure, i.e., the engine, must be designed for scalability and reliability. Poor design results in slow dashboards and failing pipelines, which quickly erode user satisfaction. Modern success often involves automated DataOps and CI/CD pipelines that ensure changes are tested and deployed with the same rigor as professional software.
5. User Satisfaction: The Exceptional Experience
Finally, we must treat our internal data consumers like customers. Successful data products boast an exceptional user experience. This is often measured using a Net Promoter Score (NPS) erode, which captures how satisfied users are with the product's usability and documentation.
When data products are self-describing, they include the business semantics (e.g., a plain-English definition of active user) so that Finance and Sales are no longer arguing over whose report is correct.
Conclusion
The anatomy of a successful data product is the practical difference between a data swamp and a high-performance data engine. It requires a dedicated Data Product Manager to act as the strategic visionary, bridging the gap between business needs and technical capabilities. When you treat your data like a product, it stops being a burden and starts behaving like infrastructure you can actually build a future on.
