Introduction
Building sophisticated models on unstructured, messy data doesn’t scale intelligence; it only automates chaos at speed.
There is a quiet panic in boardrooms right now. The pressure to build, buy, and deploy AI tools has pushed organizations into a frantic race to bypass foundational engineering. Teams are throwing highly sophisticated models at chaotic, siloed data environments, hoping the technology will somehow sort out the mess on its own.
This is a structural misunderstanding of how artificial intelligence works.
An AI model is an inference engine built on top of your historical data architecture. If that architecture is broken, the technology will simply automate and amplify your existing liabilities at a scale and velocity that manual QA processes cannot keep up with.
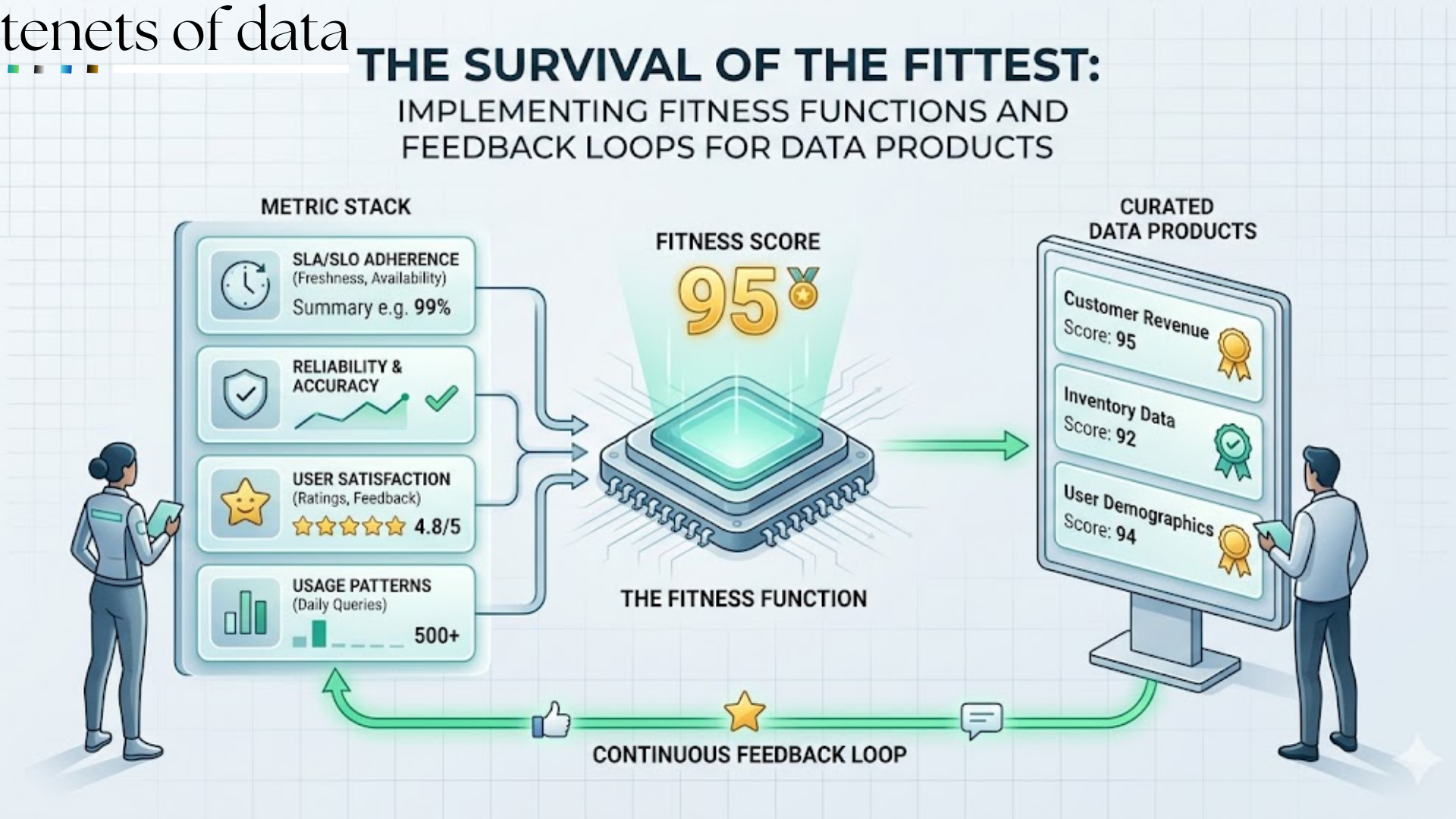
If you want to build AI tools that deliver actual, compounding business value, you have to do the boring work first: commit to a rigid data governance framework before writing a single line of model code.
1. The Pre-AI Checklist: Why Governance Must Come First
Skipping straight to implementation stems from the illusion that modern models are smart enough to parse unstructured chaos. They aren't. While traditional software processes data through strict, deterministic logic, AI operates probabilistically. It identifies patterns across massive volumes of information.
Without a governance framework in place first, your AI initiatives will hit three immediate walls:
The Amplification of Error
If your databases are cluttered with duplicate profiles, obsolete fields, or unverified inputs, the model will institutionalize these flaws. It treats noise as a signal, generating deeply flawed insights with high confidence. You aren't just scaling intelligence; you are scaling mistakes.
The Auditing Nightmare
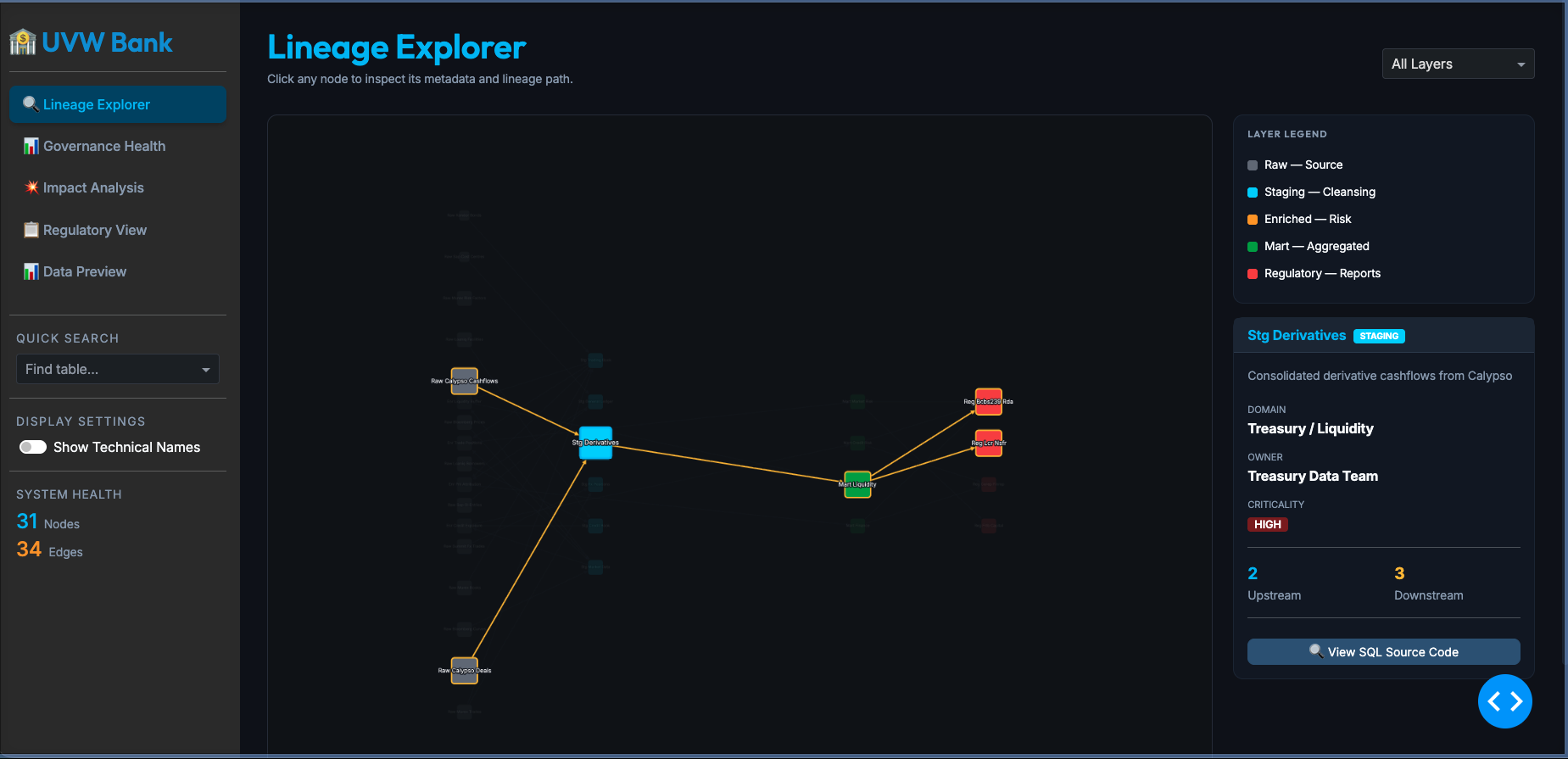
You cannot safely audit an AI tool if you cannot trace the data that feeds it. Governance establishes data lineage, a clear, documented map of where data originates, how it is transformed, and where it is stored. Without this, tracing the root cause of a model hallucination or a biased automation decision is like looking for a needle in a digital haystack.
Accidental Exposure
AI tools naturally break down internal data silos. That is their superpower, but without strict data classification protocols, it is also a massive liability. A robust governance framework partitions sensitive customer data and proprietary IP before ingestion. Without this step, you risk a model exposing restricted payroll data or proprietary code to unauthorized users via simple chat prompts.
2. The Production Trap: Why Governance Is Never "Finished."
Getting your data clean enough for launch is only the first step. The real complications begin once your systems go live. Data governance cannot be treated as a static milestone, a checklist to complete, sign off on, and file away.
AI systems interact with data dynamically, which means your governance must adapt continuously.
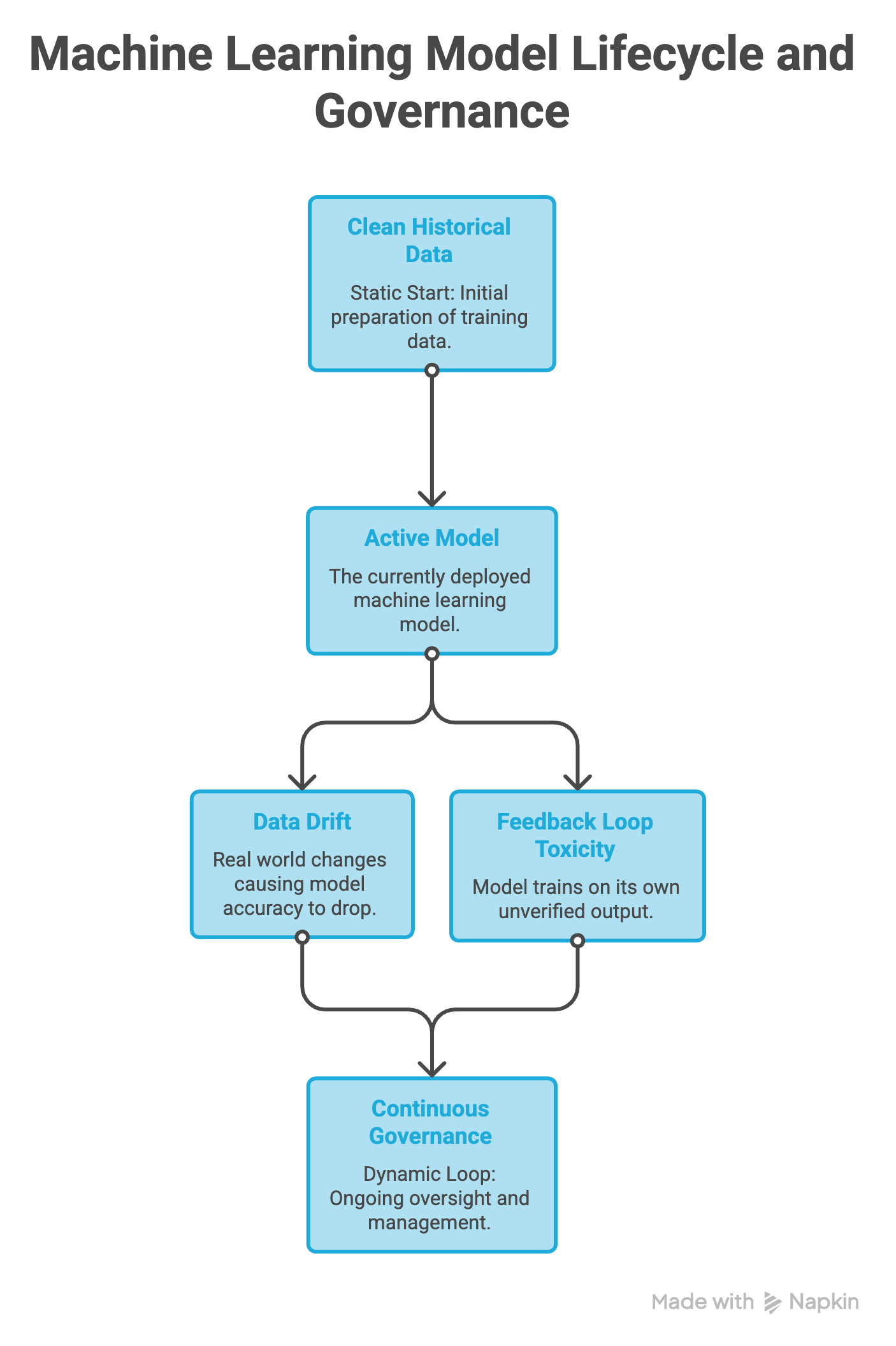
Fighting Silent Decay (Data Drift)
Real-world data is unstable. Market conditions shift, consumer behaviors evolve, and operational workflows change. When the live data entering your systems begins to diverge from the historical dataset used to train the model, the system experiences drift. Its predictive accuracy decays silently in the background. Continuous governance pipelines are required to monitor, flag, and update training inputs to keep pace with current realities.
Stopping the Echo Chamber
AI tools don't just consume data; they produce it. The outputs, summaries, and automated logs generated by these systems flow right back into your enterprise ecosystem. Without a continuous loop to evaluate and scrub this machine-generated data, you risk creating a feedback loop where models train on their own unverified outputs, compounding errors over time.
Navigating Regulatory Shifting Sands
The legal landscape surrounding algorithmic accountability, copyright, and data privacy is moving incredibly fast. A data compliance posture designed today will likely be obsolete within twelve months. Continuous iteration allows you to update access policies and consent mechanisms seamlessly, without tearing down your core infrastructure and starting over.
Conclusion
Building AI tools on top of an ungrounded data ecosystem is a poor approach that only breeds disaster. The sophistication of the above-ground technology cannot compensate for the instability below.
True AI readiness is never about how complex your models are. It is about the structural integrity of the data assets you feed them. If you want to build a system that lasts, start by governing the data.