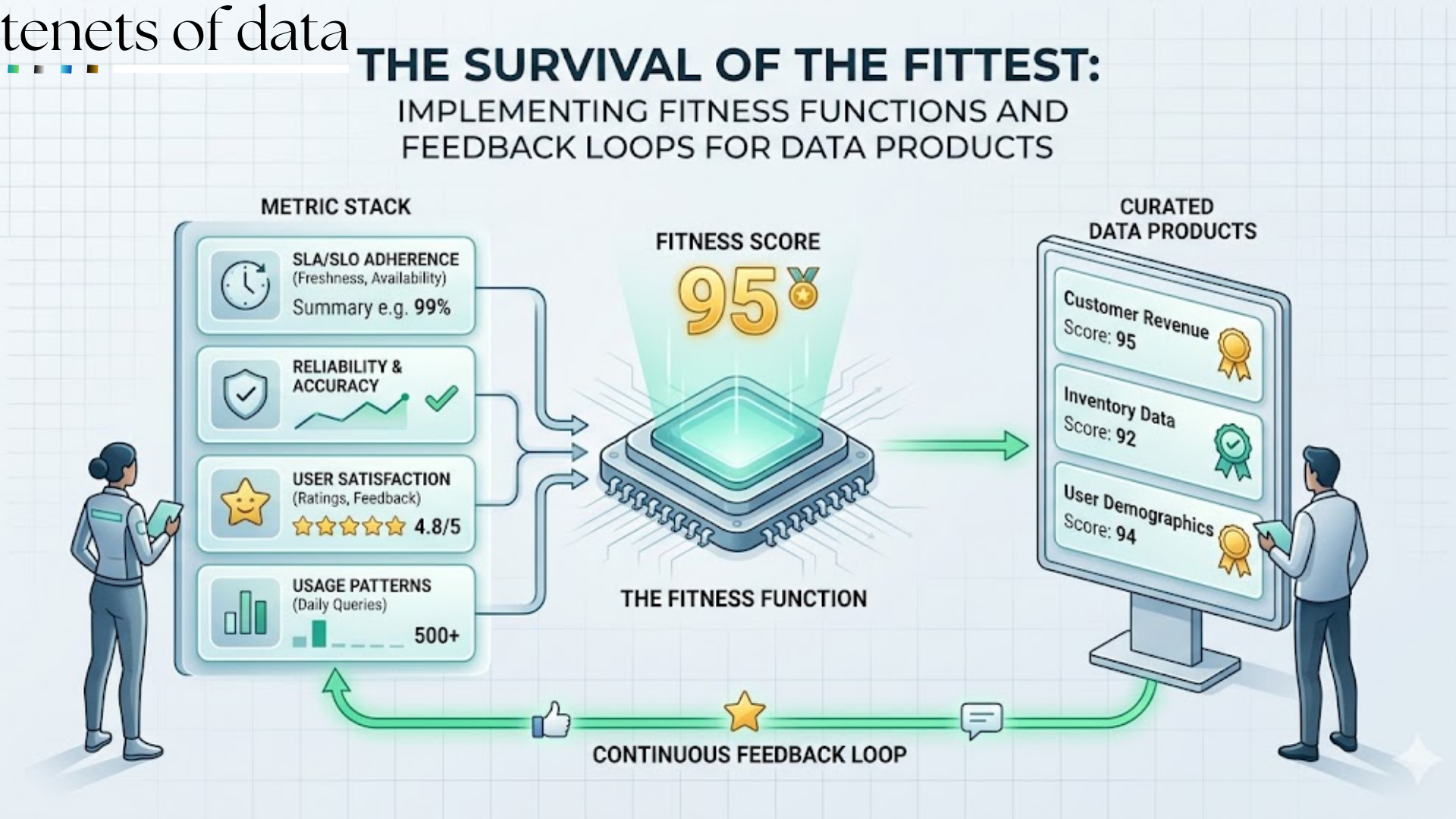
Introduction
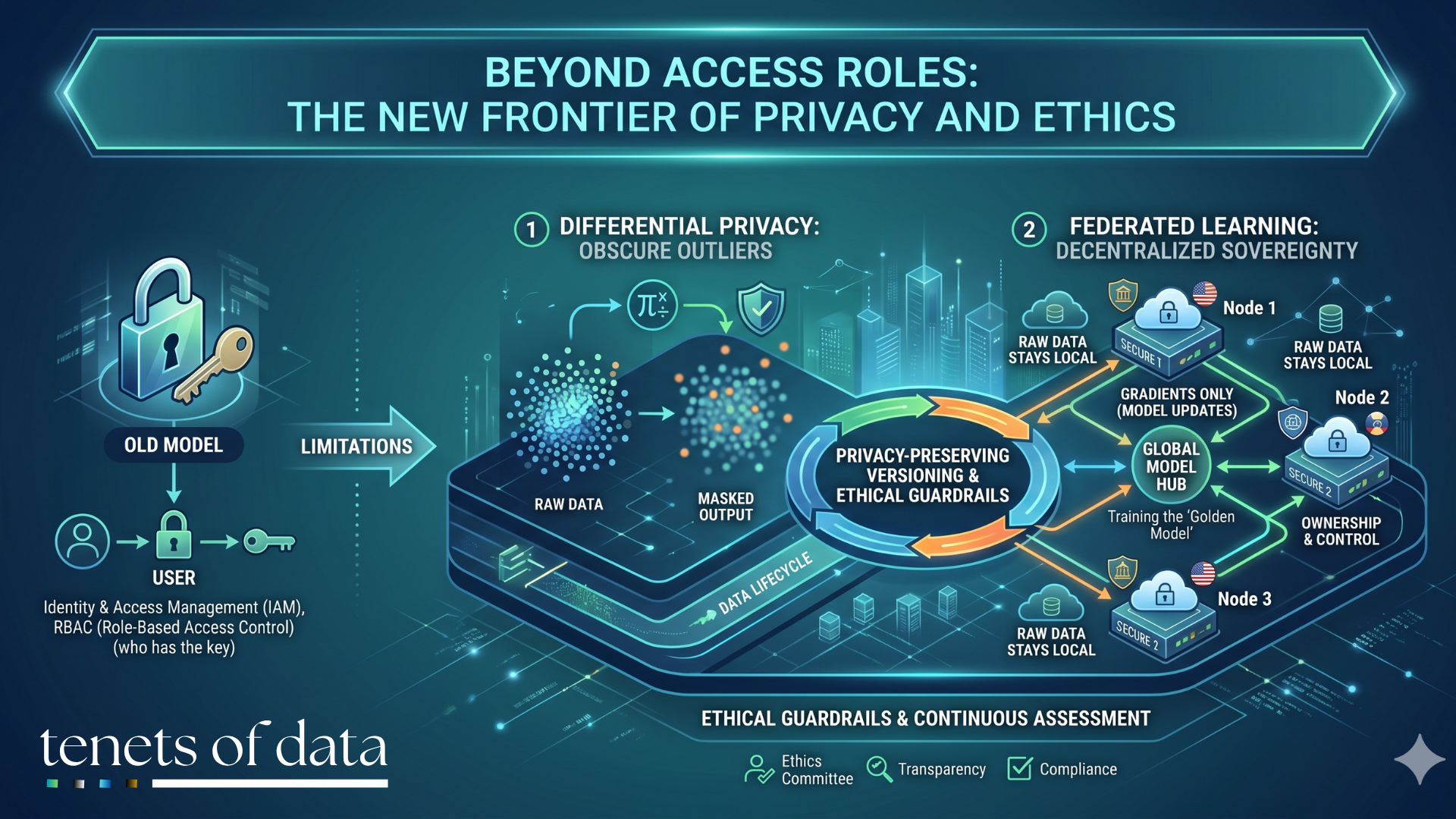
The digital economy now runs on high-resolution data products, yet the traditional perimeter-based security model is reaching its limit. Simply controlling who enters the room is no longer enough when the data itself can be used to reverse-engineer sensitive identities. As datasets become more interconnected, organizations must look beyond basic access roles to find a framework where privacy is a mathematical certainty, not just a policy. To move from simple compliance to a truly ethical data posture, organizations are adopting privacy-preserving versioning, which embeds advanced mathematical and architectural guardrails directly into the data product lifecycle.
Differential Privacy
One dangerous anti-pattern in data sharing is the assumption that anonymized data is safe data. Even when names and identifiers are removed, the more precise a dataset is, the more likely it is to retain outliers. These are unique records that serve as breadcrumbs for re-identification when combined with other public resources. For example, a dataset might not name a specific patient, but it might contain a unique combination of zip code, birth date, and a rare medical condition that makes that individual easy to unmask.
Differential privacy addresses this by mathematically adding noise to the data generation process. This technique creates a tempered pattern that intentionally obscures these outliers while preserving the statistical integrity of the overall dataset. By making this a standard property of data product generation, organizations can guarantee that their synthetic or masked test data remains useful for analysis without ever crossing the line into excessive disclosure. Integrating these algorithms into the versioning process ensures that every snapshot of a data product maintains a consistent, high level of privacy that cannot be reversed through subsequent updates.
Federated Learning: Sovereignty Through Decentralized Training
In many highly regulated sectors, such as healthcare or international finance, raw data cannot be moved because it must remain within a specific jurisdiction or domain to preserve sovereignty. Traditional integration models that require data centralization become a honey pot for attackers and a legal liability for compliance officers.
Federated learning solves this move-or-lose dilemma by reversing the flow of computation. Instead of bringing the data to the model, this approach brings the training process to the data. Multiple decentralized sources collaborate to train a shared machine learning model, but the raw, sensitive data never leaves its original location. Only the model updates, known as gradients, are shared with a central coordinator to refine the golden version of the model, which is then sent back to the contributors. This sovereignty-by-design enables robust, cross-domain analytics while ensuring that individual data providers maintain absolute control and ownership of their assets.
Building the Ethical Guardrail
A mature data product strategy recognizes that ethics are not a point-in-time assessment but an ongoing requirement. Organizations are now establishing cross-functional ethics committees to evaluate how combined datasets might enable unintended insights, particularly as data products are fused across different domains. These committees work to ensure that transparency principles are upheld, clarifying which transformations were applied to the data and whether synthetic noise was used for protection.
By shifting these privacy and ethical checks left into the development and versioning phases, governance ceases to be a bureaucratic roadblock. Instead, it becomes an automated enabling layer that allows analysts and data scientists to experiment with confidence.
Conclusion
The transition from passive governance to active, privacy-preserving engineering is necessary for any enterprise seeking to lead in an era of advanced analytics. By moving these ethical checks into the core development phase, companies transform compliance from a burden into a competitive advantage. Data products that are private by design do more than protect users: they enable sharing, collaboration, and innovation without the looming threat of a data breach. Ultimately, embedding differential privacy and federated learning into the fabric of your data products enables an enterprise to scale its intelligence without sacrificing its legal or ethical integrity.